- 1. pandas:
- 2. numpy:
- 3. matplotlib:
- 4. scikit-learn:
- 1.1 数字类型
- 1.2 字符串
- 1.3 列表
- 1.4 元组
- 1.5 字典
- 1.6 集合
- 2.1 选择结构
- 2.2 循环结构
初识 python

什么是 python?
python 英文直译为大蟒蛇。而我这里说的 python,是一种编程语言。
关于 python 的一些小知识:
(1)python 的第一个公开版本正式发行,是在 1991 年。而 Java 语言最早是在 1995 年发行的,比 Python 还晚了 4 年。
(2)python 是一种解释性的语言:运行的时候才进行编译。
(3)python 是 Guido Van Rossum 在某个圣诞节假期无聊的时候写的一门语言。
为什么选择 python?

"Life is short, you need Python"


从上图可以看出,pandas、numpy、matplotlib 这几个包的使用率在过去的几年里显著地提升。

可以看到,和 python 相关的标签主要有:
1. pandas:
一个强大的分析结构化数据的工具集。它的使用基础是 Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
2. numpy:
NumPy 是使用 Python 进行科学计算的基础软件包。除其他外,它包括:
(1)功能强大的 N 维数组对象。 (2)精密广播功能函数。 (3)集成 C/C+和 Fortran 代码的工具。 (4)强大的线性代数、傅立叶变换和随机数功能。
3. matplotlib:
matplotlib 是一个 Python 的绘图库,它能够输出的图形包括折线图、散点图,直方图等。 mapplotlib 的设计哲学是:你可以仅仅只用一丢丢甚至一行命令行来创建一个简单的平面图!假如你想看你数据表示的柱状图,你也不需要进行如下繁杂的步骤:初始化对象,调用方法,设置属性等等
4. scikit-learn:
Scikit-learn 项目最早由数据科学家 David Cournapeau 在 2007 年发起,需要 NumPy 和 SciPy 等其他包的支持,是 Python 语言中专门针对机器学习应用而发展起来的一款开源框架。
结论:
It's all about data science! python 这门语言给我们提供了丰富的工具库,对于没有很多编程基础的人而言,是非常友好的!
学习之前
在学习 python 之前,我们需要先安装环境。小白推荐安装 anaconda,anaconda 不用安装一些配置文件
安装 Anaconda
Anaconda:是一个包含 180+安装好的计算工具包。其包含的科学包包括:conda, numpy, scipy, ipython notebook 等。
1.百度搜索 Anaconda
2.进入官网
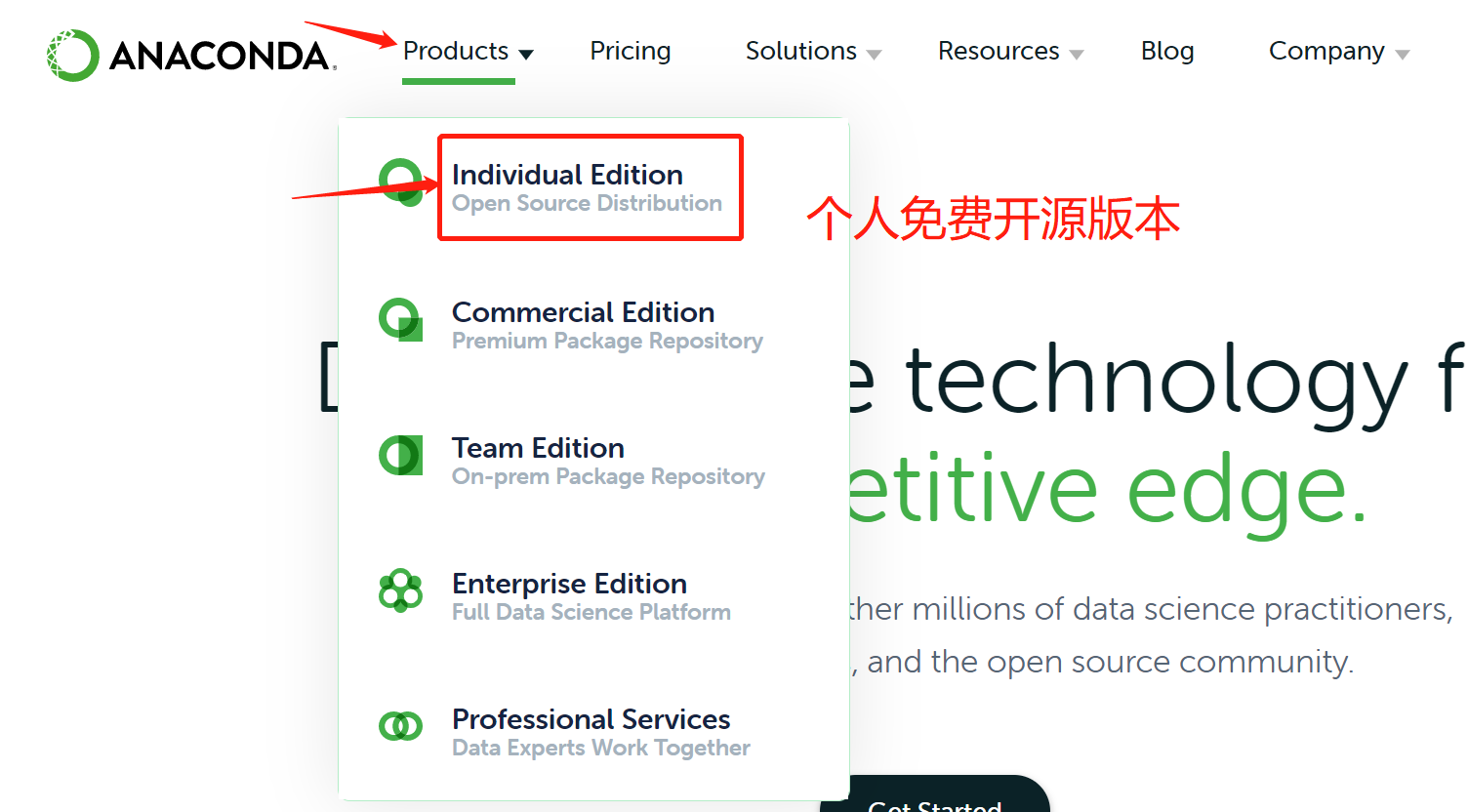
3.选择安装的版本

4.以 window(64 位)为例
打开安装包
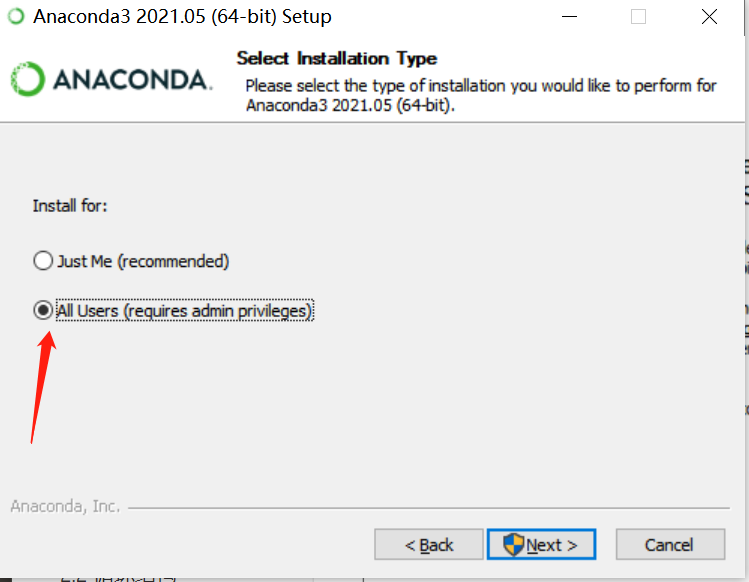
5.默认 next,这一步选择 All Users
6.Anaconda 可以安装在 C 盘,也可以安装在其他盘。
这里以安装在 C 盘为例
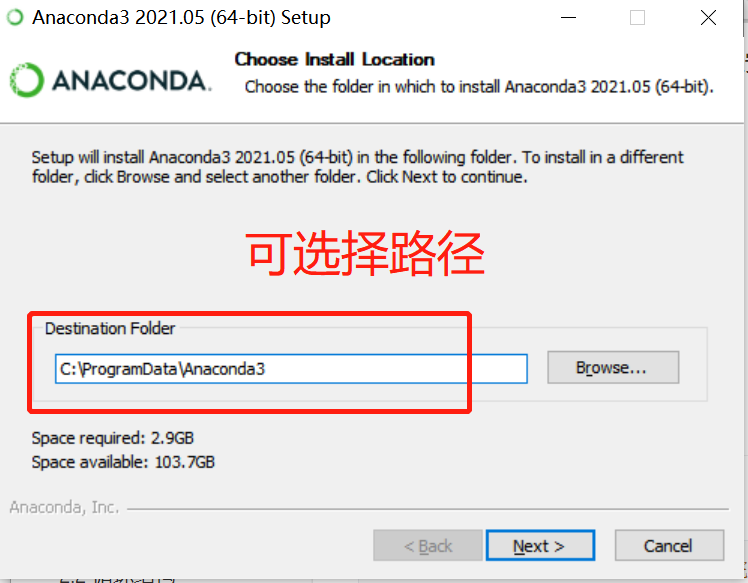
7.Anaconda 可以选择是否配置环境变量,如果要添加最好手动添加,默认添加容易出现问题
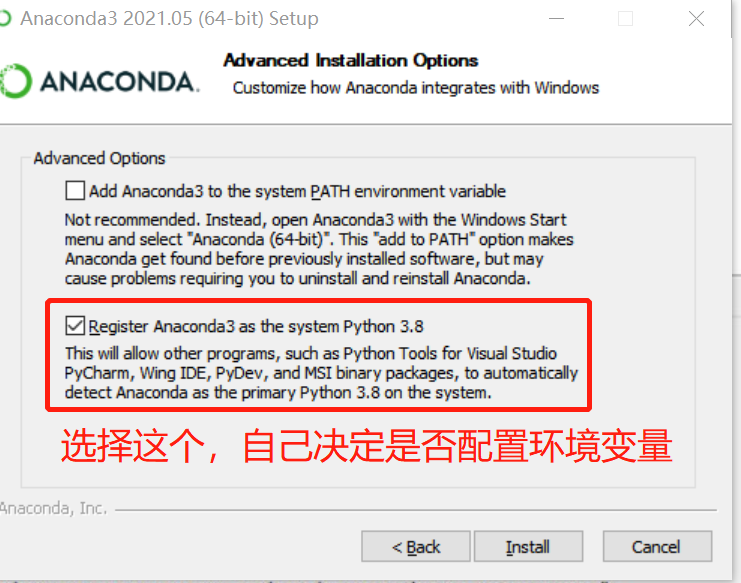
选择 Install(安装)
8.等待安装
9.安装完成
10.打开
点击电脑左下角——开始——Anaconda3(64-bit)——Jupyter Notebook
Jupyter Notebook:分块运行代码单元,数据分析必备
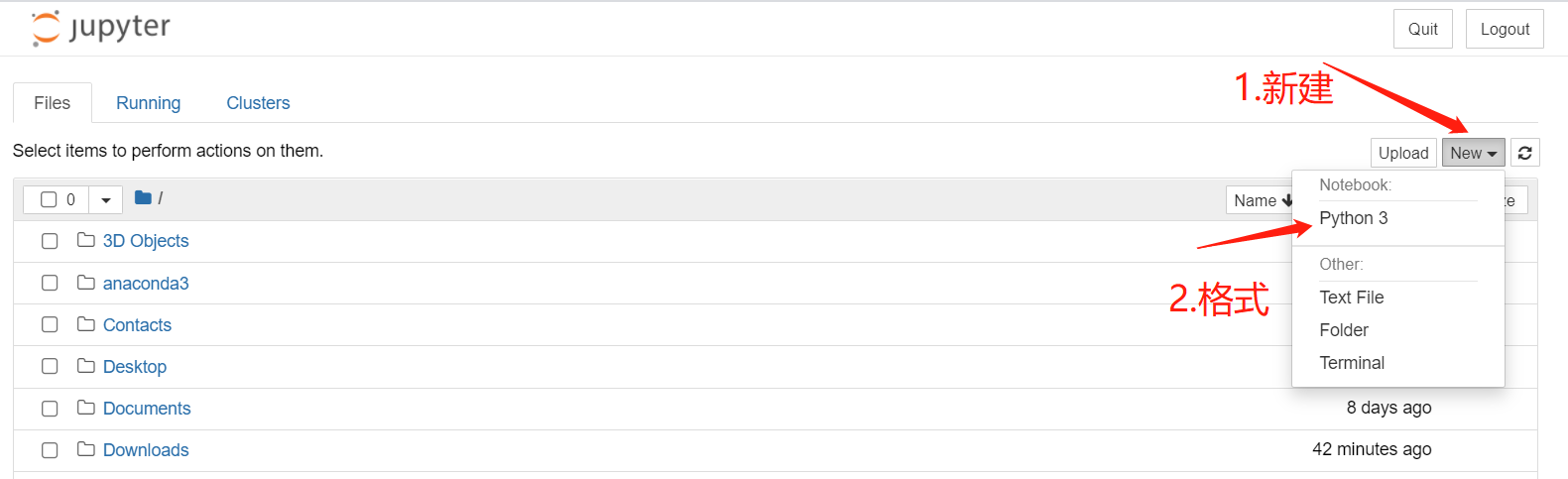
11.在浏览器里有以下这个界面就说明可以开始写代码啦
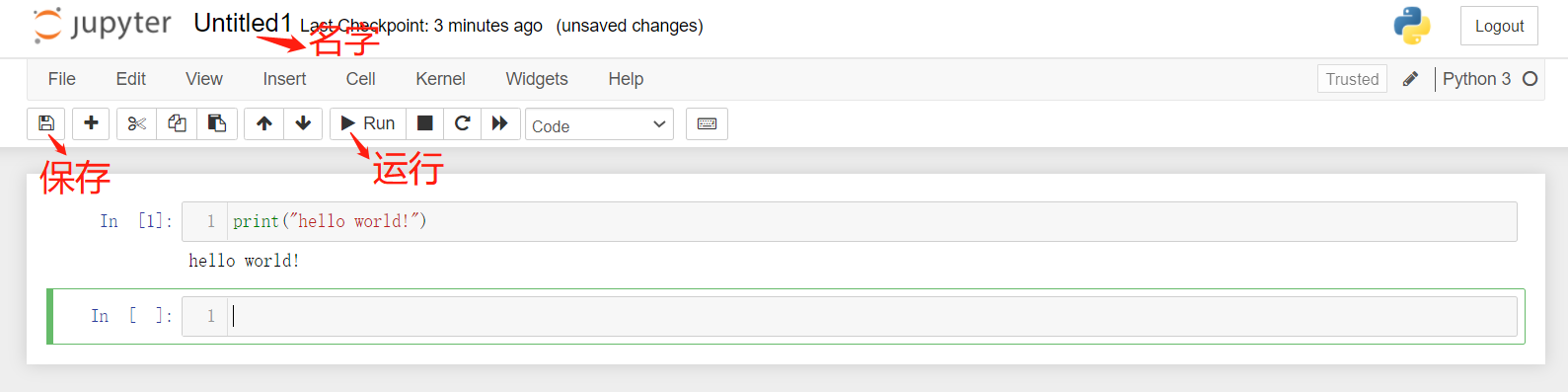
开始写代码吧,jupyter notebook 的使用方法可以自行百度,边写边学,当遇到问题的时候,要在搜索引擎中得到解决问题的答案。
学习第一步
”hello world!“
# 在这里输入你们的代码,首先让我完成学习每一个语言应该做的仪式。说出hello world!# 这里的#后面的内容代表是注解
print('hello world!')
hello world!
1 python 标准的数据类型
| 类型 | 解释 |
|---|---|
| Numbers | 数字 |
| String | 字符串 |
| List | 列表 |
| Tupe | 元组 |
| Dictionary | 字典 |
| Set | 集合 |
1.1 数字类型
a=33=a# 程序里的等号,和我们日常生活里的等号有点不一样=的左边,代表一个符号,是一个变量。=的右边,代表一个值。=的作用,就是赋值。
File "
b=2#创建了一个变量b,把数值2赋值给这个变量print(b)
2
# 日常生活的等于在python中就是==c=2c==2
Ture
# type 表示的就是类型print(type(3))# int ——integer整数print(type(3.5))# float——小数/浮点数
<class 'int'> <class 'float'>
# 创建了一个变量aa=3print(a)print(type(a))print('\n') # 这个就代表的换行a=3.4print(a)print(type(a))
3 <class 'int'>
3.4<class 'float'>
note: 数据类型是不允许改变的,这就意味着如果改变 Number 数据类型的值,将重新分配内存空间。(感兴趣的可以自己试一下)。
# id(object)返回的是对象的“身份证号”,唯一且不变,但在不重合的生命周期里,可能会出现相同的id值。print(id(a))b=aprint(id(b))b=3print(id(b))
1312615232880 1312615232880 1312543041904
a=int(a)a
3
a=3b=4a+b
7
1.2 字符串
a='a'# 这代表什么意思# 创建了一个变量a# 把‘a'值赋值给aprint(a)
a
a='元旦快乐!#$%#$%#@FFDDSAWERFSDF@@R#FGVDGER'print(a)
元旦快乐!#
bob='hello world'print('bob =',bob,2,3,3,4,'元旦快乐','\n')print('bob')
bob = hello world yh 3 3 4 元旦快乐
bob
# 和数字一样字符串可以用于加减# 但是,字符串的'+'代表的是一种拼接a='hello'b='world'c=a+'^'+bprint(c)a='(0'b='_'c='0)'print(a+b+c)
hello^world (0_0)
a='hello'b='hello'print(a)print(b)
hello hello
#note:字符串一定要用引号框起来。这是为了区分。比如:a='a'# 没有意义#这里a代表变量,'a'代表的是a这个字符。a
'a'
mystring='Hello! This is my {},and this is my {}.{}!'.format('brother','sister','goodbye')# 使用format方法可以让字符串变得更加灵活。print(mystring)
Hello! This is my brother,and this is my sister.goodbye!
1.3 列表
happy=[1,2,3,4,5,6]# 列表的特定就是有序的,可索引的。# 坑!列表的索引是从0开始的。print(happy[0])# 比如你要查看列表的第三位的数据,你要用3-1=2这个索引进行检索。print(happy[3-1])print(happy[2])
1 3 3
a=3b=2.6print(a,b)b=int(b)#int是向下取整print(b)
3 2.6 2
c=list(range(5))print(c)
[0, 1, 2, 3, 4]
# range表示一个范围。range(8)表示的是0-8这个范围。但是它是一个半闭半开区间。[0,8)bob=list(range(8))# 显式地创建一个列表,强制地把range(8),转换成了一个list。print(bob)
[0, 1, 2, 3, 4, 5, 6, 7]
bob[:5] # bob[0:5]# 要bob的前5个数据print(bob[0:5]) # 表示从0开始,到5结束(记住,这是一个半闭半开区间,5是取不到的)。
[0, 1, 2, 3, 4]
#len——length长度。 len(a)表示的是a的长度。print(bob)print(bob[0:len(bob):2]) # 以2为步长
[0, 1, 2, 3, 4, 5, 6, 7] [0, 2, 4, 6]
# 可以看到,列表内的元素可以是列表,也可以是字符串,甚至不要求列表内元素的数据类型统一。bob=['bob',2,[1,2,3]]bob
['bob', 2, [1, 2, 3]]字符串和数组之间可以相互转换
# 这个大家可以自己后面去理解,这里就不再说了
mystring='hello world'my_string_list=mystring.split()#split默认以空格切片,返回列表,列表里存在两个字符串' '.join(my_string_list)#join以空格组合列表里的两个字符串
'hello world'
1.4 元组
a=tuple([2,3,4])a
(2, 3, 4)
# 元组和列表十分类似,具有相同的索引方法。最大的不同在于,元组的数据不可被修改。# 因此元组往往会用于a[0:-1:1]
(2, 3)
ls=[1,2,3]ls[2-1]=4ls# 列表是可以用索引来进行修改的
[1, 4, 3]
t=tuple([2,3,4])t[2-1]=4t# 列表是可以用索引来进行修改的# 元组除了不能被修改,其他和列表一模一样
TypeError Traceback (most recent call last)
TypeError: 'tuple' object does not support item assignment
1.5 字典
字典是一种键值对,我们可以通过键,来访问值
mydic={'amy':4}mydic
{'amy': 4}
mydic['amy']
4 答疑:
()括号一般表示的是一个函数/方法.()里面一般是放参数的。
print('a')# print就代表的是一个函数,一种操作。
a []括号一般用于(1)创建列表,是列表独有的标识。(2)用来索引的
ls=[1,2,3]#这么写,就表示ls是一个列表。print(ls)
[1, 2, 3]
ls[1] # 找到ls的第2个元素。
2{}括号一般用于创建字典,是字典独有的标识。
mydic={'bob':1}print(mydic)print(mydic['bob'])
{'bob': 1}1
1.6 集合
#集合里面没有相同的元素set([1,2,2,2,3,3])
{1, 2, 3}
{1,2,2,2,3,3}
{1, 2, 3}
a = {1,2,3,4,5}b = {3,4,5,6,7,8}
#a与b的并集a.union(b)
{1, 2, 3, 4, 5, 6, 7, 8}
a | b
{1, 2, 3, 4, 5, 6, 7, 8}
#a和b的交集a.intersection(b)
{3, 4, 5}
a & b
{3, 4, 5}
2 流程控制
按照执行流程划分,Python 程序也可分为 3 大结构,即:顺序结构、选择(分支)结构和循环结构。
Python 顺序结构就是让程序按照从头到尾的顺序依次执行每一条 Python 代码,不重复执行任何代码,也不跳过任何代码。 Python 选择结构也称分支结构,就是让程序“拐弯”,有选择性的执行代码;换句话说,可以跳过没用的代码,只执行有用的代码。 Python 循环结构就是让程序“杀个回马枪”,不断地重复执行同一段代码。
这边主要讲选择结构以及循环结构。
2.1 选择结构

#input()函数——输入函数,让我们的程序接收一个输入。print('请输入a')a=input()print(a)
请输入 A:4 4
print('请输入a')a=int(input())print('请输入b')b=int(input())print('结果为:')if a>b:print('a>b')elif a<b:print('a<b')else:print('a=b')
请输入 a 1 请输入 b 2 结果为: a<b
2.2 循环结构
一般来说,循环可以通过 for 和 while 关键字来实现。
for i in range(5):print(i)
0 1 2 3 4
n=0while n<5:print(n)n+=1
0 1 2 3 4 很多时候循环往往是用于遍历。
bob=['bob',1,2,3,(1,2,3)]for i in bob:print(i)
bob 1 2 3 (1, 2, 3)
3 函数
问题:函数是什么?
回答 1:函数是一种关系。例如:
回答 2:函数是组织好的,可重复使用的,用来实现单一或者相关联功能的代码段。

def myduc():print(3)
myduc()
3
def add(a,b):return a+b
add(3,4)
7
a,b=10,5def swap(a,b):return b,aprint('a,b交换之前,a={},b={}\n'.format(a,b))a,b=swap(a,b)print('a,b交换之后,a={},b={}'.format(a,b))
a,b 交换之前,a=10,b=5
a,b 交换之后,a=5,b=10 这就是你们需要掌握的基础内容了!加油呀!
接下来可以解锁第三小结,开始训练啦!